데이터 전처리 (Preprocessing) (1) - [Python]
머신러닝 모델링 전에 주어진 데이터의 전처리 과정은 필수적입니다.
일반적으로 선형회귀, RandomForest, XGBoost 등의 모델을 훈련시키기 위해서는 적절한 데이터의 형태가 필요합니다.
또한, 실제 데이터는 clean하지 않은 경우가 대다수이며 이 데이터를 그대로 사용한다면 모델의 성능이 안 좋을 가능성이 매우 크기 때문에 전처리 과정은 매우 중요하다고 볼 수 있습니다.
전처리 과정을 간단한 data set을 이용해서 살펴봅시다.
1. Feature(Predictor) 와 Response 나누기
import pandas as pd
import numpy as np
data = pd.read_csv('data.csv')
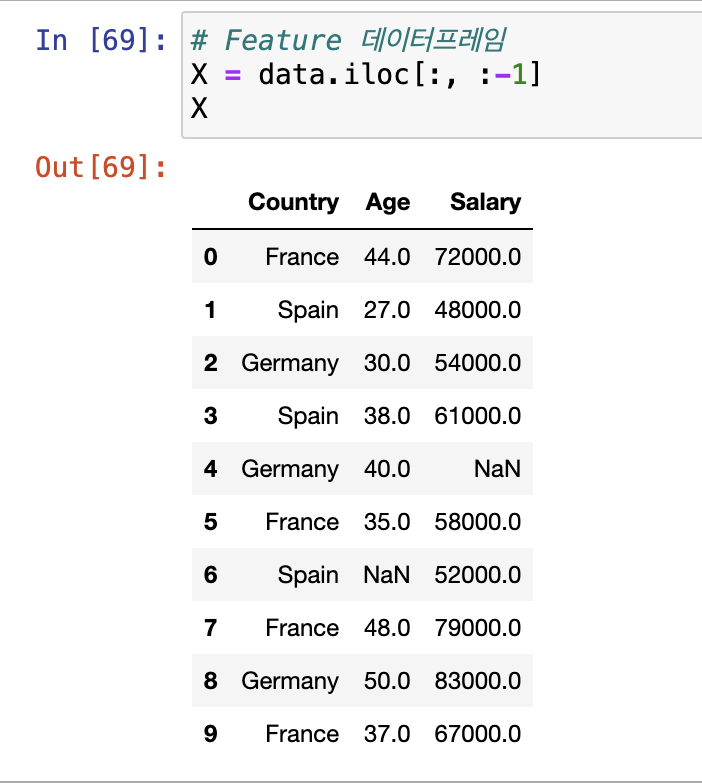
데이터를 살펴보면, Feature로는 Country, Age, Salary가 있고
이에 따라 총 10개의 관측치가 존재합니다.
Age와 Salary열에 각각 결측치도 1개씩 존재하는 것을 볼 수 있네요.
우리가 해야 할 일은 Country, Age, Salary 열을 이용해서 각 행의 Purchased를 Yes 또는 No로 분류하는 것입니다.
오늘은 이 결측치를 어떻게 처리할 것인가, 그리고 Country 같은 범주형 변수를 어떻게 인코딩할 것인가에 대해서 생각해보겠습니다.
먼저 Feature 행렬과 Response 벡터를 나누는 작업이 필요합니다.
이를 numpy array로 생성해야 나중에 모델을 학습시키고 평가할 수 있기 때문에 다음과 같은 코드가 필요합니다.
# Feature 행렬
X = data.iloc[:, :-1].values
# Response 벡터
y = data.iloc[:, -1].values
iloc 함수는 인덱스를 이용하여 데이터프레임의 원하는 값을 찾는 함수입니다.
[ , ] 안에는 각각 행과 열의 인덱스가 들어가는데요, : 는 모든 인덱스를 의미합니다. -1은 마지막 인덱스를 의미하구요.
뒤에 .values를 적으면 numpy array로 반환되고 적지 않으면 데이터프레임으로 반환됩니다.

2. 결측치 처리
주어진 데이터의 개수가 아주 많고 결측치가 그 중 약 1% 정도라면, 그냥 삭제해버려도 모델 성능에 큰 영향을 끼치지는 않을 것입니다.
하지만 주어진 데이터의 개수가 적을 때, 결측치를 삭제한다면 학습이 잘 되지 않아 모델 성능에 큰 영향을 끼칠 것입니다.
지금 보고 있는 data set은 관측치의 개수가 10개로 매우 적습니다.
따라서 결측치가 있는 부분을 해당 열의 평균으로 대체하겠습니다.
먼저 data set을 다시 보겠습니다.
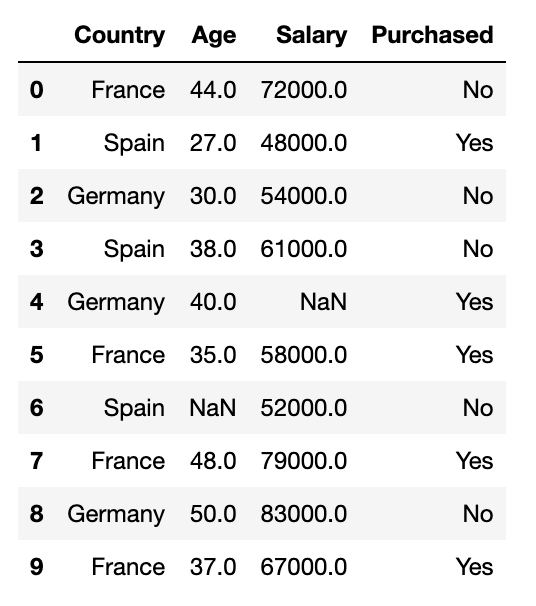
Age 열은 인덱스 6, Salary 열은 인덱스 4에 결측치가 존재하는 것을 볼 수 있습니다.
이제 결측치를 각 열의 평균으로 대체해보겠습니다.
먼저 코드를 살펴보면,
from sklearn.impute import SimpleImputer
# 인스턴스 생성
imputer = SimpleImputer(missing_values = np.nan, strategy = 'mean')
# 문자열을 제외한 열에 fit 메서드 적용
imputer.fit(X[:, 1:3])
# transform 메서드를 이용하여 결측치를 평균값으로 대체
X[:, 1:3] = imputer.transform(X[:, 1:3])
먼저 필요한 라이브러리를 import 해줍시다.
그 다음, 결측치를 채워줄 imputer라는 SimpleImputer 클래스의 인스턴스를 생성합니다.
저희는 결측치를 평균으로 채워줄 것이기 때문에 missing_values의 인자로는 np.nan, strategy의 인자로는 'mean'을 입력합니다.
이제 생성한 인스턴스에 fit 메서드를 적용시켜 우리가 결측치를 채워넣을 행렬을 fit 해줍니다.
문자열은 평균을 취할 수 없기 때문에 X[:, 1:3]으로 제외시켜줍시다.
마지막으로 transform 메서드를 이용하여 결측치를 평균값으로 대체시키면 됩니다.

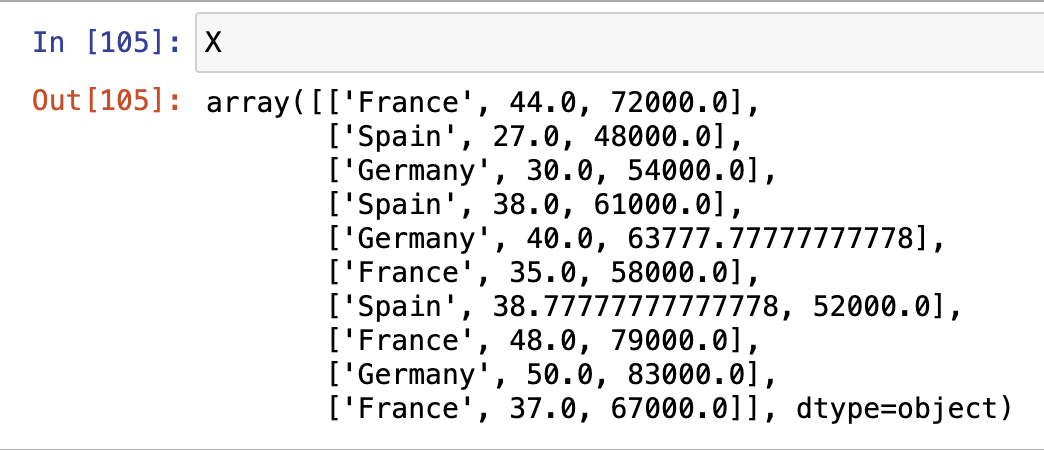
위와 같이 결측치가 각 열의 평균값으로 대체된 것을 확인할 수 있습니다.
3. 범주형 데이터 인코딩 (Label Encoding, One-Hot Encoding)
설명변수 행렬의 첫 번째 열은 'France', 'Spain', 'Germany'의 원소로 이루어진 범주형 자료입니다.
컴퓨터는 텍스트를 인식하지 못하기 때문에 이해 할 수 있는 숫자의 형태로 만들어줘야 합니다.
따라서 문자열을 숫자로 인코딩해야 하는데, 만약 France = 0, Spain = 1, Germany = 2으로 인코딩한다고 생각해봅시다.
| France (기존 컬럼값) | 0 |
| Spain (기존 컬럼값) | 1 |
| Germany (기존 컬럼값) | 2 |
위와 같이 인코딩하는 방법을 Label Encoding이
라고 합니다.
나름 일리가 있어보이나 문제점이 존재합니다.
0, 1, 2로 인코딩 하게 되면, 세 국가의 순서가 실제로는 중요하지 않으나 머신러닝 모델이 순서에 대한 중요도를 부여할 수 있습니다.
그렇게 되면 유의미한 결과값을 도출하기 어려워집니다.
따라서 다른 방법이 필요한데, 그 중 하나가 One-Hot Encoding입니다.
One-Hot Encoding을 이용하면 순서가 없는 데이터에 순서를 부여하는 Label Encoding의 문제점을 해결할 수 있습니다.
먼저 어떻게 적용되는지 보겠습니다.
| France | Spain | Germany | |
| France (기존 컬럼값) | 1 | 0 | 0 |
| Spain (기존 컬럼값) | 0 | 1 | 0 |
| Germany (기존 컬럼값) | 0 | 0 | 1 |
위와 같이 원래 컬럼값이 France라면, France에 해당하는 인덱스 값은 1, 나머지는 0으로 인코딩 됩니다.
Spain, Germany의 경우도 마찬가지로 인코딩 되는 것을 볼 수 있습니다.
따라서 One-Hot Encoding을 하게 되면 순서를 부여하지 않게 되고 데이터에 연속성이 없다는 것을 컴퓨터에게 알려줄 수 있습니다.
이제 코드를 이용해서 One-Hot Encoding을 구현해봅시다.
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
# 인스턴스 생성
ct = ColumnTransformer(transformers = [('encoder', OneHotEncoder(), [0])], remainder = 'passthrough')
# One-Hot Encoding
X = ct.fit_transform(X)
먼저 필요한 라이브러리를 import 해줍니다.
그 후, 컬럼을 Encoding 해주도록 ColumnTransformer 클래스의 인스턴스를 생성합니다.
transformers 인자는 [ ] 안에 튜플 형식으로 넣어주면 되는데요, 첫 번째로는 '변환의 유형', 두 번째는 '인코딩에 사용할 클래스 이름', 세 번째는 '적용할 열의 인덱스'를 넣어주시면 됩니다.
remainder 인자에 'passthrough'를 작성하지 않으면 인코딩한 열만 반환이 됩니다. 저희는 모든 열이 필요하므로 적어줍시다.
마지막으로 fit_transform 메서드를 이용해서 One-Hot Encoding을 구현하면 됩니다.
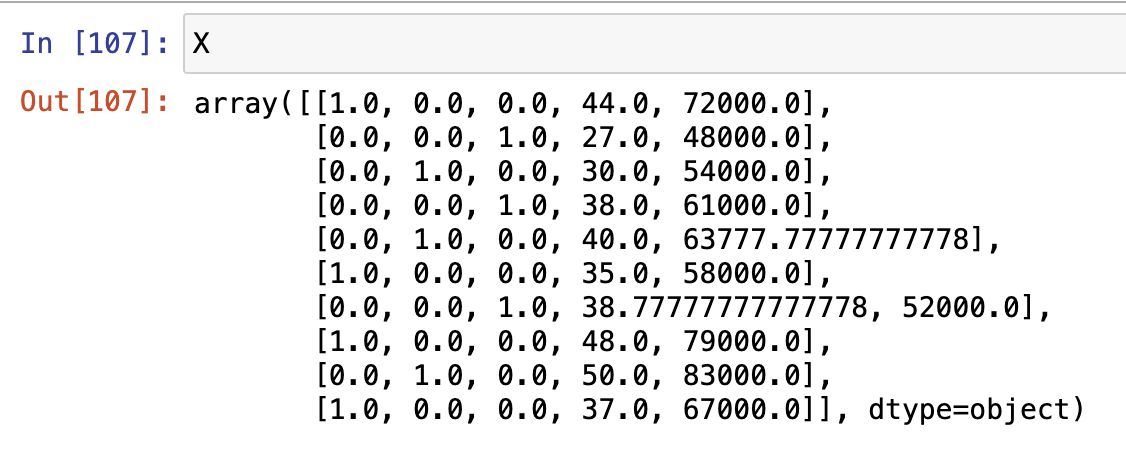
위와 같이 문자열로 이루어진 범주형 자료가 [1, 0, 0], [0, 0, 1] 등으로 인코딩 된 것을 확인할 수 있습니다.
이제 반응변수 y를 인코딩 해보겠습니다.

y는 우리가 predictor를 이용하여 각 데이터를 분류해야 할 값이 들어있는 response 입니다.
따라서 Label Encoding을 이용해도 문제가 생기지 않습니다. (순서가 존재하지 않더라도)
from sklearn.preprocessing import LabelEncoder
# 인스턴스 생성
le = LabelEncoder()
# Label Encoding
y = le.fit_transform(y)
위와 같이 라이브러리를 import 하고 인스턴스를 생성한 뒤, fit_transform 메서드를 이용하여 Label Encoding을 구현하면 됩니다.

No = 0, Yes = 1로 인코딩 된 것을 확인할 수 있습니다.